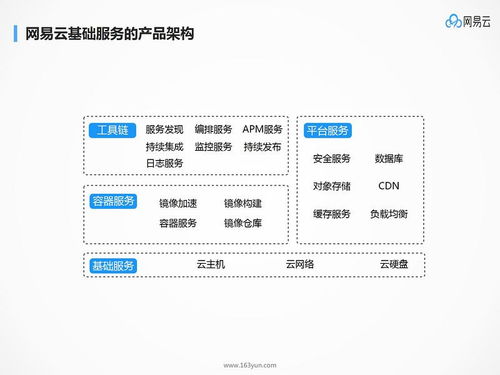
在數字化轉型的浪潮中,數據已成為企業最核心的資產之一。網易作為中國領先的互聯網科技公司,其在大數據領域的實踐和基于微服務的應用架構設計,為行業提供了寶貴的經驗。本文將深入探討網易如何構建高效的數據處理和存儲支持服務,以支撐其多元化的業務場景。
一、大數據實踐的基石:數據處理與存儲的挑戰與策略
網易的業務覆蓋游戲、電商、音樂、教育等多個領域,每天產生海量的結構化與非結構化數據。面對如此龐大的數據量,網易構建了一套多層次、高可用的數據處理與存儲體系。
1. 數據處理流程的優化:
網易采用了批處理與流處理相結合的混合架構。對于需要實時響應的業務,如游戲內玩家行為分析、網易云音樂的推薦系統,采用Apache Flink等流處理框架,實現毫秒級的延遲。而對于歷史數據分析和報表生成,則使用Apache Spark進行高效的批處理。通過Lambda架構或Kappa架構的靈活應用,確保了數據處理既滿足實時性,又兼顧準確性。
2. 存儲服務的分層設計:
數據的存儲并非“一刀切”。網易根據數據的訪問頻率、重要性及成本考量,設計了冷熱分層的存儲方案。熱數據(如近期用戶交易記錄)存儲于高性能的分布式數據庫(如MySQL集群、NoSQL數據庫)或內存數據庫中,以確保快速訪問;溫數據(如月度報表數據)可能存儲于HDFS或對象存儲中;冷數據(如歷史日志)則歸檔至成本更低的存儲介質。通過數據湖與數據倉庫的融合,實現了原始數據的低成本存儲與高效分析查詢的平衡。
二、微服務架構下的數據服務設計
微服務架構以其靈活性、可獨立部署和擴展的優勢,成為網易應用現代化的關鍵選擇。微服務化也帶來了數據管理的復雜性——數據分散、一致性問題、跨服務查詢等挑戰。網易通過以下實踐應對這些挑戰:
1. 數據庫按服務拆分(Database per Service):
每個微服務擁有自己獨立的數據庫,這確保了服務的自治性和技術棧選擇的自由。例如,用戶服務可能使用關系型數據庫管理用戶檔案,而推薦服務可能使用圖數據庫來存儲用戶關系網絡。這種模式避免了單點故障,并提高了系統的整體可擴展性。
2. 事件驅動架構保障最終一致性:
在分布式系統中,強一致性難以實現且代價高昂。網易廣泛采用事件驅動模式,通過消息隊列(如Kafka、RocketMQ)發布領域事件。當某個服務更新其數據時,會發布一個事件,其他相關服務訂閱該事件并異步更新自己的數據視圖,從而實現數據的最終一致性。例如,訂單服務創建訂單后發布“訂單創建”事件,庫存服務和物流服務監聽并相應更新狀態。
3. 構建統一的數據查詢與聚合層:
為解決跨微服務的數據查詢難題,網易設計了API網關和專用的數據聚合服務(BFF - Backend for Frontend)。對于復雜的查詢需求,如需要聯合用戶信息、訂單歷史和商品詳情的儀表盤,可以通過一個聚合服務向各個微服務發起調用,或者利用CQRS(命令查詢職責分離)模式,將查詢操作導向一個專為讀取優化的數據存儲(如Elasticsearch或只讀副本數據庫),避免影響核心事務處理性能。
4. 數據存儲支持服務化:
網易將底層的數據存儲與計算能力封裝成內部服務,如“統一配置服務”、“元數據管理服務”、“數據訪問服務”等。這些服務為上層業務微服務提供標準化的接口,屏蔽了底層HDFS、HBase、Redis等不同存儲系統的復雜性。開發人員無需關注數據具體存儲在何處、如何分片,只需通過服務API即可安全、高效地存取數據,大大提升了開發效率并降低了運維成本。
三、實踐中的關鍵技術與工具棧
網易的大數據與微服務生態構建于一系列成熟的開源與自研技術之上:
- 計算引擎:Apache Flink(流處理)、Apache Spark(批處理)、自研的QSQL(交互式查詢)。
- 存儲系統:HDFS、HBase、Cassandra、Redis、MySQL、以及自研的對象存儲服務。
- 消息中間件:Apache Kafka、RocketMQ,用于事件傳遞和服務解耦。
- 微服務治理:Spring Cloud、Dubbo,結合自研的服務注冊發現、配置中心和鏈路追蹤系統。
- 數據管理:Apache Atlas(元數據管理)、Airflow(工作流調度),確保數據血緣清晰、任務調度可靠。
四、與展望
網易的大數據實踐與微服務架構設計,核心在于“分層解耦”與“服務化”。通過將復雜的數據處理流程拆解為獨立的、可復用的服務組件,并輔以統一的管理和治理平臺,不僅支撐了業務的快速增長與創新試錯,也構建了穩定、高效、易擴展的技術中臺。隨著云原生、Serverless和AI技術的深入融合,網易的數據處理與存儲支持服務將更加智能化、彈性化,持續為業務創造價值。
對于正在或計劃進行類似架構演進的企業而言,網易的經驗表明:明確的數據治理策略、合適的技術選型、以及堅定不移的服務化改造,是駕馭數據洪流、構建敏捷數字企業的關鍵路徑。